
论文
推理层面缓解幻觉
为了缓解幻觉问题,提出了几种对比解码(CD)策略,通过引入扰动输入来减少幻觉
VCD——视觉对比解码(Visual Contrastive Decoding)
早期工作尝试在小规模的VLMs中,通过执行细粒度模态对齐或通过数据增强减少对象共现的统计偏差来实现。
主要分析了视觉不确定性对 LVLMs 中物体幻觉的两个主要原因的影响,即统计偏差和单模态先验(即语言先验)
auto-regressively (自回归):大白话: AI生成答案时,是一个词一个词地往后蹦,而不是一瞬间把整句话说出来。
在AI生成答案的时候,幻觉之所以会发生,就是因为它错误地给那些图片里根本没有的东西对应的词,分配了很高的概率(分数)。
Octopus
其是对VCD的一种改进
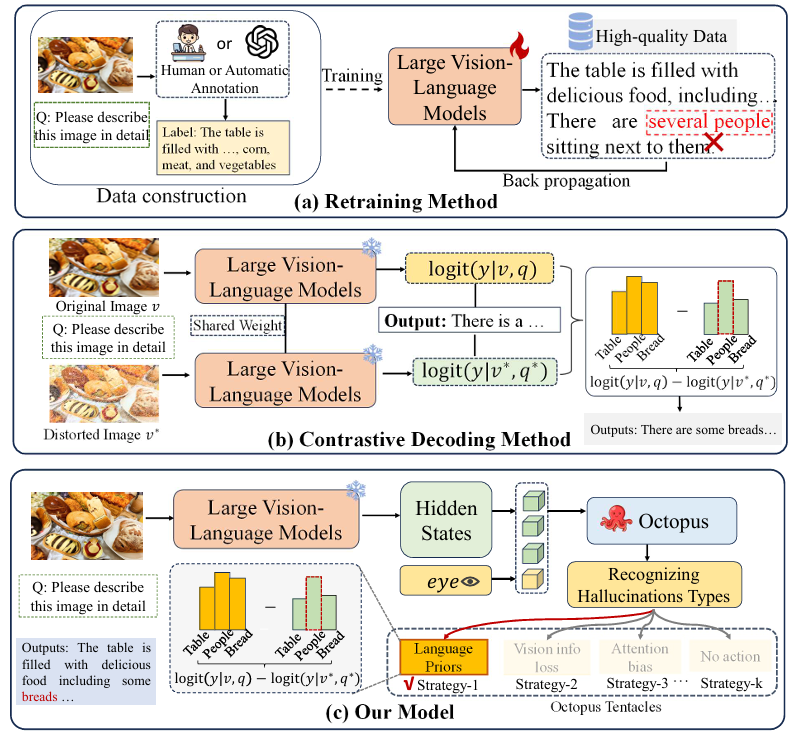
现有的研究方法分为两种思路: 第一种方法(a)依赖于构建高质量的指令微调数据并重新训练模型来抑制幻觉 而(b)对比解码则是对每个生成步骤中来自原始输入的logit分数与来自修改后输入的logit分数进行对比,这些 CD 方法侧重于设计一对新的 v∗ 和 q∗ 来缓解幻觉问题。
但这些 CD 方法大多对所有样本和生成步骤应用相同的干扰方式 每种 CD 方法仅对特定的幻觉样本有效,使用单一的 CD 策略会导致次优结果。
工作:侧重于指导模型动态组织对比解码流程,并根据不同的输入选择合适的CD策略
首先构建了一个基于Transformer的模块和一个可学习的 token,以自适应地识别幻觉类型,类似于章鱼的眼睛。根据不同的决策,每种 CD 策略被视为一个“触手”,用于执行特定的对比操作。最后,借助直接偏好优化(DPO)或强化学习,Octopus 可以轻松实现优化。
不同的样本(或标记)会遭遇各种形式的幻觉问题
大型视觉语言模型通常由三个关键组件构成: 视觉编码器(像CLIP)、大型语言模型(像LLAMA)、跨模态对齐模块
为减轻大语言视觉模型(LVLMs)中的幻觉问题,已经提出了基于数据的再训练方法和对比解码(Contrastive Decoding,CD)方法。基于数据的方法旨在提高数据质量以减少幻觉现象。例如,一些研究引入了负样本数据和反事实数据来缓解幻觉问题。对数据集进行清洗以尽量减少噪音和错误。50, 55 注释了高质量的幻觉数据集,通过微调抑制幻觉的发生。相比之下,CD 方法通过比较原始输入和失真输入的输出分布来应对幻觉,而无需改变模型的权重。例如,19通过抵消语言先验来缓解幻觉,而 11 则通过优化视觉提示来处理幻觉。与上述方法不同,我们的工作专注于自适应地选择最合适的 CD 策略,以缓解不同的幻觉问题。
AI模型是像“挤牙膏”一样,一个词一个词地往外蹦答案的,而不是一口气把整句话说出来^a1
是下一个标记的logit分数,表示在时间步t之前生成的响应
Logit 分数是模型在决定下一个要说什么词时,在内部对所有可能的候选词给出的一个原始、未加工的“信心分数”或“可能性评分”。这个分数越高,模型就越认为这个词是正确的答案。它是模型做出最终选择前最重要的一步。
对比解码(CD) 原始视觉图像v和文本查询q,另一个来自扰动的输入v* 和q*
^a2
CD策略: 1、VCD 侧重于克服语言先验。它使用高斯噪声掩码生成扭曲的视觉输入 v∗,而查询文本 q 保持不变。 2、M3ID 通过减少视觉信息丢失来缓解幻觉问题。它通过掩码构建查询文本 q∗,并将视觉输入 v 独立提供给 LVLMs 作为扭曲输入 3、AVISC 通过最小化注意力偏差来缓解幻觉。它使用不包含与查询相关信息的盲标记构建新的视觉输入 v∗。
样本级幻觉 (Sample-Level Hallucination)是一种宏观、结果导向的视角 令牌级幻觉 (Token-Level Hallucination)是一种微观、过程导向的视角
幻觉的原因是混合的,每个生成步骤都面临不同形式的挑战。
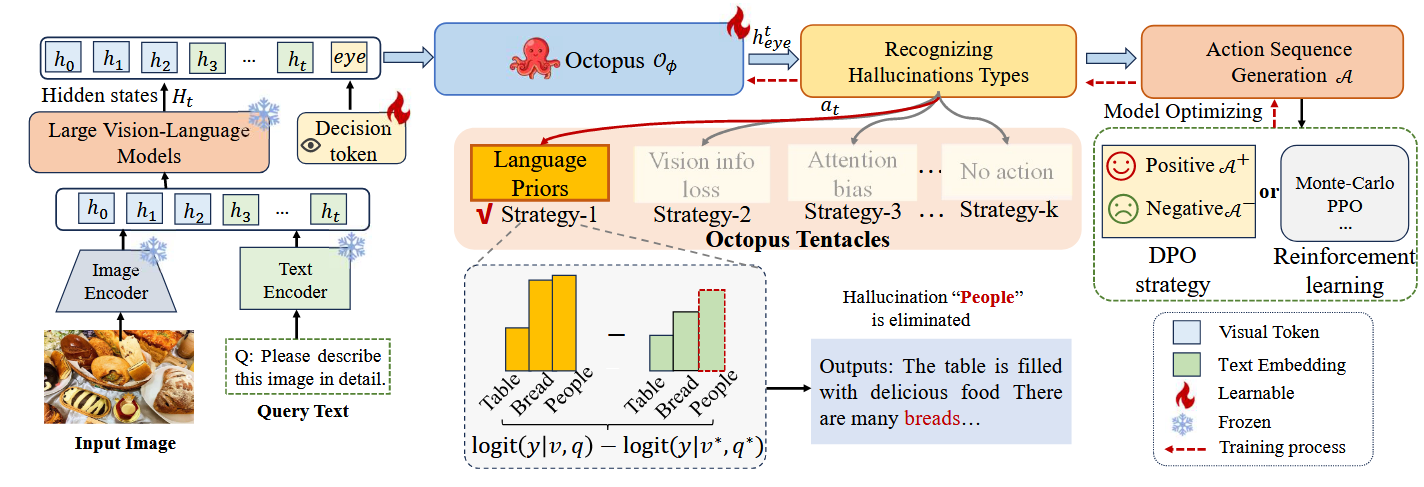 “章鱼 (Octopus)”框架由两个关键部分组成:决策令牌“眼睛”和它的“触手”。具体来说,我们首先利用“眼睛”来识别幻觉的类型,然后运用这些“触手”在每一个生成步骤中去解决特定的幻-觉问题。最后,我们的模型将通过DPO或其他强化学习方法进行优化。
“章鱼 (Octopus)”框架由两个关键部分组成:决策令牌“眼睛”和它的“触手”。具体来说,我们首先利用“眼睛”来识别幻觉的类型,然后运用这些“触手”在每一个生成步骤中去解决特定的幻-觉问题。最后,我们的模型将通过DPO或其他强化学习方法进行优化。
方法
模型结构
具体而言,我们首先构建一个基于标准Transformer 的模块 ,其中 表示 Transformer 结构的参数。根据[[VCD#^a1|公式1]]可知,每个时间步 会同时受 、 和 影响。因此,这些来自大视觉语言模型(LVLMs)的隐藏状态(即 、 和 )会与一个决策标记 (其中 是隐藏状态的维度)一起输入到 中。为简化表述,我们用 表示第 个生成步骤之前的序列,其中 是每个标记的隐藏状态。而可学习的标记 可被视为 “章鱼之眼”。公式如下:
其中, 和 分别表示来自 和 序列的对应输出。 和 分别表示位置嵌入与拼接操作。得益于自注意力机制, 能够自适应地聚合来自其他隐藏状态的信息。
然后,使用一个轻量且简单的多层感知机(MLP)将 映射为动作向量 ,其中 表示候选策略的数量。 在本文中,我们在每个步骤中构建了四个动作空间,分别对应第 3.2 节中的三种策略(即VCD、M3ID和AVISC),以及一个空动作(即不执行任何 CD 策略。这里,我们使用“触手”来表示这些候选的 CD 动作。对于每个 ,其动作向量 通过以下方式获得:
其中argmax是指选择最大值索引的操作,softmax是激活函数,得到工作流,其中N是响应长度。是一个独热向量,它代表在文本生成的第 t个时间步,Octopus模型最终决定要使用的那个具体的对比解码策略。
数据构建流程(无监督,无需人工标注):
- 随机探索 (Generate):针对同一个输入,让模型随机地在每一步选择一个“触手”策略,生成10个不同的结果(文本)。这10个结果背后对应了10个不同的“行动序列”(
A)。 - 自动评估 (Evaluate):使用一个自动化的指标CHAIR(分数越低,幻觉越少)来给这10个结果打分。
- 构建偏好对 (Pair):从这10个结果中,挑选一个分数好的(低CHAIR分)作为**“赢家”(Winner, A+),再挑选一个分数差的(高CHAIR分)作为“输家”(Loser, A-)**。
- 进行训练:将大量的
(赢家A+, 输家A-)偏好对喂给模型。DPO算法会调整模型参数,使得模型未来更倾向于执行像A+这样的行动序列,而不是像A-那样的。
E即求平均值,其中 x = (v,q) 是输入序列,设置为1
评论区
评论加载中...